LongHorizonUI
面向 GUI Agent 长链路任务的统一鲁棒自动化框架
A Unified Framework for Robust Long-Horizon Task Automation of GUI Agent
1中国科学院大学 · 2腾讯 · 3佐治亚理工学院 · 4清华大学 · 5南开大学 · 6深圳河套学院 1University of Chinese Academy of Sciences · 2Tencent · 3Georgia Institute of Technology · 4Tsinghua University · 5Nankai University · 6Shenzhen Loop Area Institute
概要
Abstract
多模态大模型(MLLM)驱动的 GUI Agent 在短任务上表现出色,但面对超过 10–15 步的长链路任务时,感知漂移、定位偏差与决策误差会逐步累积,导致成功率骤降。 LongHorizonUI 针对这一问题提出了三项核心设计: (1) 增强感知模块(OCR + 控件检测 + 关键区域模板修复)为每个 UI 元素分配唯一索引,确保跨步状态可追踪; (2) 深度反思决策,通过结构化的 JSON Schema 强制进行历史验证、目标一致性检查和动作可解释性推理; (3) 补偿式执行器,基于 Index → Relative → Absolute 三级退化策略完成动作落地,同时持续监控执行进度并在失败时触发回滚。 此外,我们还构建了 LongGUIBench 基准(371 场景,平均 22.1 步),用于系统评估长链路能力。
MLLM-driven GUI Agents perform well on short tasks, but when task sequences exceed 10–15 steps, perception drift, localization errors, and decision mistakes accumulate, causing a steep drop in success rate. LongHorizonUI addresses this with three key designs: (1) A Multimodal Enhanced Perceiver (OCR + icon detection + template repair) that assigns a unique index to each UI element for trackable cross-step state representation; (2) A Deep Reflection Decider that enforces history validation, goal-consistency checks, and action-explainability reasoning via a structured JSON Schema; (3) A Compensating Action Executor with an Index → Relative → Absolute fallback strategy, continuous progress monitoring, and rollback on failure. We also introduce LongGUIBench (371 scenarios, avg. 22.1 steps) for systematic long-horizon evaluation.
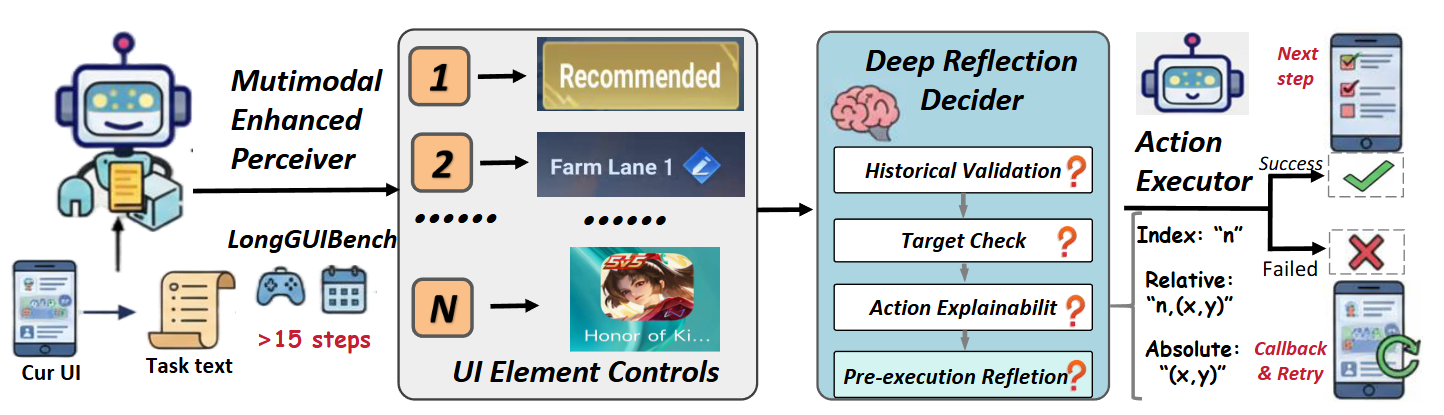
方法概览
Method Overview
1) 基准数据集:LongGUIBench
1) Benchmark: LongGUIBench
现有 GUI 基准大多侧重短任务(典型 <10 步),难以暴露长链路场景下的误差累积问题。 为此,我们构建了 LongGUIBench:所有任务至少 15 步(平均 22.1 步),涵盖 15 款通用应用(147 条任务链)和 13 款游戏(207 条高复杂度场景),合计 4508 张截图。 数据由 6 位专业测试人员录制,经跨模态对齐和人工去噪后生成标准化中间表示,每步均标注有操作类型、bbox 坐标及 UI 状态元数据。
Most existing GUI benchmarks focus on short tasks (typically <10 steps) and fail to reveal error accumulation in long-horizon settings. We built LongGUIBench: every task requires at least 15 steps (mean 22.1), covering 15 general apps (147 task chains) and 13 games (207 complex scenarios), totaling 4,508 screenshots. Data was recorded by 6 professional testers, then cross-modally aligned and manually cleaned to produce standardized annotations with action type, bbox, and UI metadata per step.
147 条任务链 · 15 款应用 · 平均 19.5 步 · 含多级菜单、实时输入验证等典型交互
147 task chains · 15 apps · avg. 19.5 steps · multi-level menus, real-time input validation, etc.

207 条高复杂度链路 · 13 款游戏 · 平均 23.7 步(最高 37 步)· 覆盖装备管理、活动参与等核心机制
207 complex chains · 13 games · avg. 23.7 steps (up to 37) · equipment management, event participation, etc.
2) LongHorizonUI 框架
2) LongHorizonUI Framework
LongHorizonUI 的核心思路是将"语义决策"到"物理执行"之间的不确定性分层处理。 首先将屏幕解析为带唯一索引的元素集合,为后续所有环节提供稳定锚点; 然后在决策层通过结构化三级反思,确保每一步动作与任务目标一致且可执行; 最后在执行层采用多策略坐标映射与实时验证,必要时自动退化或回滚。 这一闭环设计使得 10–15 步后常见的性能断崖得到有效推迟。
LongHorizonUI addresses the uncertainty gap from semantic decisions to physical execution in a layered manner. It first parses each screen into an indexed element set that serves as a stable anchor for all downstream stages. The decision layer performs structured three-level reflection, ensuring every action is both task-aligned and executable. The execution layer applies multi-strategy coordinate mapping with real-time verification, automatically falling back or rolling back when needed. This closed-loop design effectively delays the performance cliff typically seen after 10–15 steps.
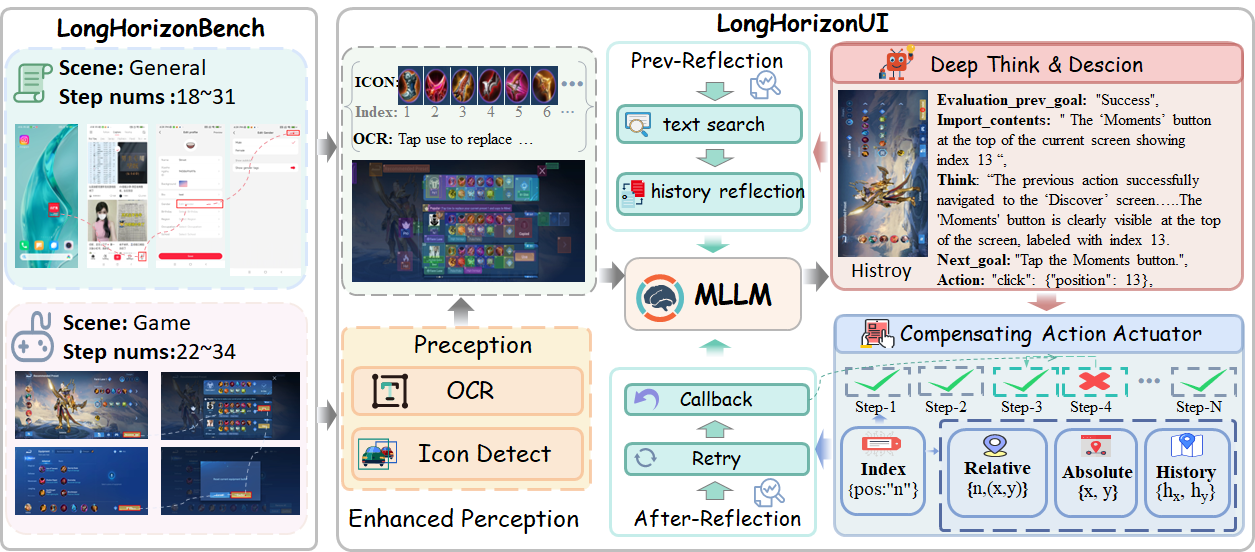
Multimodal Enhanced Perceiver
并行运行控件检测器与 OCR 模块,为每个 UI 元素分配唯一空间索引 ID。 通过 IoU 语义绑定将图标与对应文字关联(阈值 0.8 时效果最优),解决"图标+文字"复合控件的歧义。 当高优先区域未检出关键元素(如弹窗关闭按钮)时,自动触发模板修复。
Runs icon detector and OCR in parallel, assigning a unique spatial index to each UI element. IoU-based semantic binding links icons with their text (optimal at threshold 0.8), resolving ambiguity in composite controls. Template repair activates automatically when critical elements (e.g., pop-up close buttons) are missed in priority regions.
Deep Reflection Decider
通过严格定义的 JSON Schema 输出(historical_status / import_contents / think / Execute_goal / action),实现三级闭环推理: ① 历史验证——核查 UI 状态转换是否符合预期; ② 目标检查——确认当前关键信息与任务目标一致; ③ 动作可解释推理——要求模型给出定位依据后再执行。 执行前还会检查目标元素是否在当前屏幕上、动作语义是否匹配任务描述。
Enforces structured JSON Schema output (historical_status / import_contents / think / Execute_goal / action) for three-level closed-loop reasoning: ① History validation — verifies UI state transitions match expectations; ② Target check — confirms key screen info is consistent with the task goal; ③ Explainable reasoning — requires the model to justify its localization before acting. Pre-execution checks also verify the target element is on-screen and action semantics match the task description.
Compensating Action Executor
执行时按 Index(元素质心)→ Relative(框内随机采样)→ Absolute(屏幕坐标+抖动) 优先级依次尝试。 每次点击后由 MLLM 验证截图判断是否成功;若全部候选失败,触发局部重规划,仍失败则回滚到上一成功快照继续执行。 实验中回滚触发率为 12–19%,其中约 70% 最终恢复成功,仅 <3% 需完全重启。
Execution follows the priority: Index (element centroid) → Relative (random in-box) → Absolute (screen coords + jitter). After each click, the MLLM verifies the post-action screenshot. If all candidates fail, local re-planning is triggered; persistent failure invokes rollback to the last successful snapshot. In experiments, rollback is triggered in 12–19% of episodes, ~70% recover successfully, and only <3% require a full restart.
主要结果
Main Results
我们在自建的 LongGUIBench 以及公开基准(ScreenSpot、AndroidControl、GUI-Odyssey)上进行了全面实验,验证了 LongHorizonUI 在长链路推理、UI 元素定位和跨应用导航三个维度上的优势。
We conducted comprehensive experiments on LongGUIBench and public benchmarks (ScreenSpot, AndroidControl, GUI-Odyssey), validating LongHorizonUI's advantages in long-horizon reasoning, UI grounding, and cross-app navigation.
📊 LongGUIBench 长链路推理
📊 LongGUIBench: Long-Horizon Reasoning
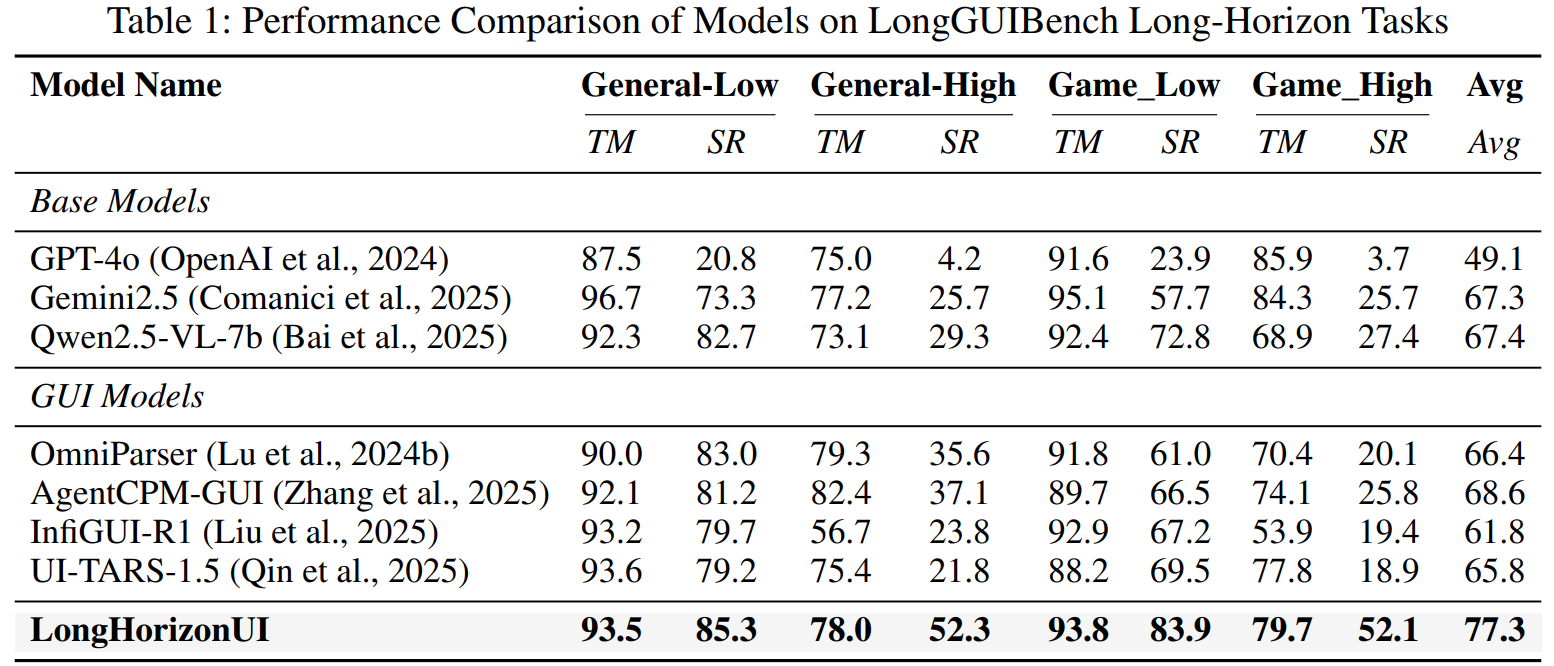
在 LongGUIBench 上,LongHorizonUI 达到 77.3% 的平均成功率,相比最强基线 UI-TARS-1.5 提升显著。 通用场景低级指令 SR 达 85.3%,高级指令 SR 达 52.3%(较 UI-TARS-1.5 分别提升 6.1% 和 30.5%); 游戏场景低级 SR 83.9%,高级 SR 52.1%,在所有对比方法中保持领先。
On LongGUIBench, LongHorizonUI achieves 77.3% average success rate, significantly outperforming the strongest baseline. General-Low SR reaches 85.3%, General-High SR 52.3% (+6.1% and +30.5% over UI-TARS-1.5); Game-Low SR 83.9%, Game-High SR 52.1%, leading across all compared methods.
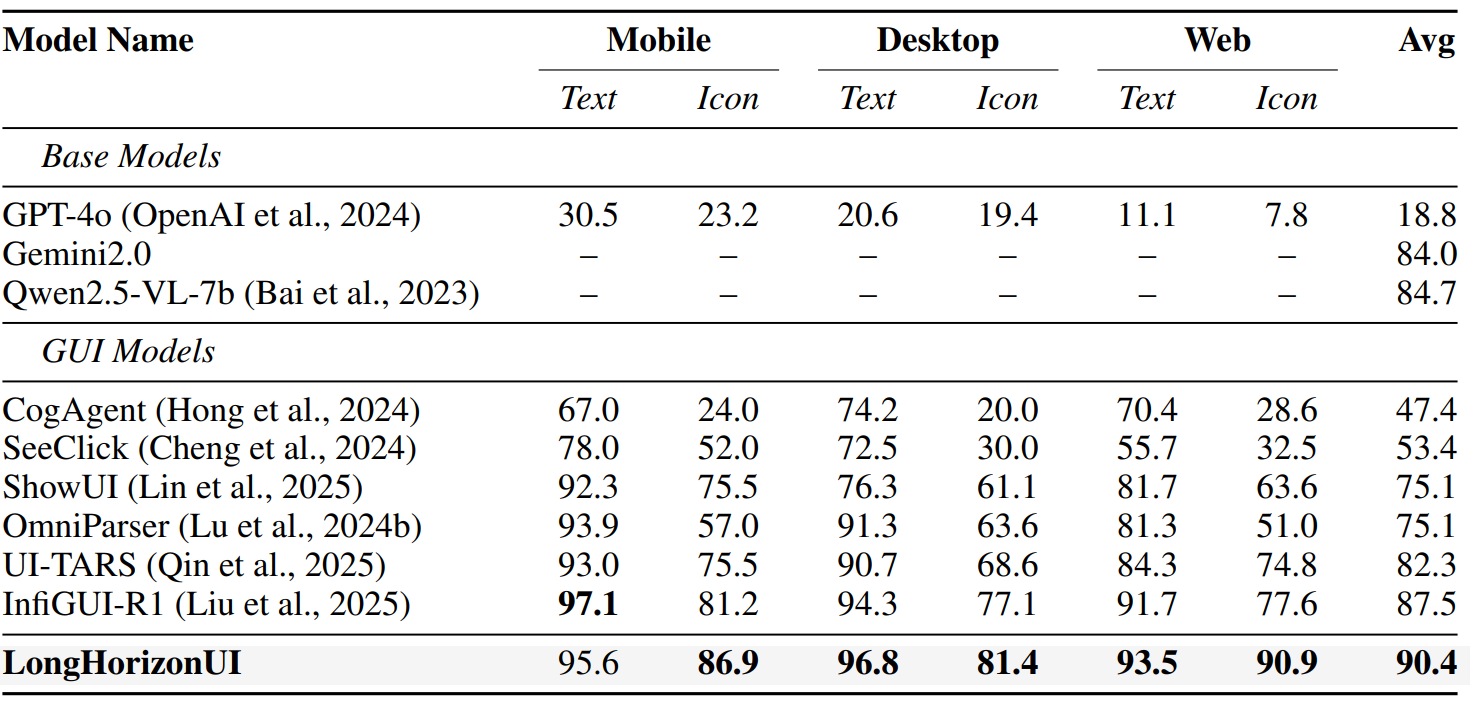
🎯 ScreenSpot 元素定位
🎯 ScreenSpot: UI Grounding
在 ScreenSpot 跨平台定位基准上,LongHorizonUI 取得 90.4% 的平均准确率,超越此前最优的 InfiGUI-R1(87.5%)。 在 Desktop Icon(81.4%)和 Web Icon(90.9%)等子项上均创下新高,表明增强感知模块的 IoU 语义绑定在图标定位上具有突出优势。
On the ScreenSpot cross-platform grounding benchmark, LongHorizonUI achieves 90.4% average accuracy, surpassing the previous best InfiGUI-R1 (87.5%). It sets new records on Desktop Icon (81.4%) and Web Icon (90.9%), demonstrating the strong grounding capability of our IoU-based semantic binding.
🧭 AndroidControl & GUI-Odyssey 导航能力
🧭 AndroidControl & GUI-Odyssey: Navigation
在 AndroidControl 和 GUI-Odyssey 上,LongHorizonUI 同样取得了一致的提升:AndroidControl-High SR 达 54.2%,GUI-Odyssey SR 达 40.5%,整体平均 65.5%,较强基线 GUI-R1-7B 提升 2.3%。 这表明 LongHorizonUI 在增强长链路鲁棒性的同时,并未牺牲短任务的基础交互能力。
On AndroidControl and GUI-Odyssey, LongHorizonUI also shows consistent improvements: AndroidControl-High SR 54.2%, GUI-Odyssey SR 40.5%, overall average 65.5%, +2.3% over the strong GUI-R1-7B baseline. This confirms LongHorizonUI improves long-horizon robustness without sacrificing short-task interaction capabilities.

用例演示
Case Demos
以下展示 LongHorizonUI 在通用应用与游戏场景中的执行过程。
Below are execution demos of LongHorizonUI in general app and game scenarios.
通用场景
General Scenario

游戏场景
Game Scenario

引用
Citation
如果本工作对您有帮助,欢迎引用:
If this work is helpful, please consider citing:
@inproceedings{anonymous2026longhorizonui,
title={LongHorizon{UI}: A Unified Framework for Robust long-horizon Task Automation of {GUI} Agent},
author={Anonymous},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={#}
}